Tutoriels vidéos
Recent Articles
Home » Archives pour 02/21/16
Simuler un lien WAN sous Linux
Simuler un lien WAN sous Linux
 Il peut être utile, dans le cadre de tests applicatifs, de simuler sur votre réseau local (LAN), les caractéristiques d'une liaison distante (WAN). En effet, vos applications peuvent très bien fonctionner sur un réseau LAN et devenir inexploitable sur des liaisons WAN.
Il peut être utile, dans le cadre de tests applicatifs, de simuler sur votre réseau local (LAN), les caractéristiques d'une liaison distante (WAN). En effet, vos applications peuvent très bien fonctionner sur un réseau LAN et devenir inexploitable sur des liaisons WAN.
Nous allons utiliser le module Net:Netem des noyaux Linux 2.6 pour simuler les caractéristiques suivantes:
- Bande passante
- Délai de transit
- Perte de paquet
- Duplication de paquet
- Re-arrangement de paquet
La configuration de ce module se fait via la commande en ligne tc.
Simuler un délai de transit constant
Le délai est le temps de transit réseau d'un paquet IP. Il dépend de pas mal de paramètres (traversé des équipements, taille des buffers et distance physique entre les deux points du réseau). Nous allons utiliser la commande delay qui va simuler un délai de transit de X ms sur tout les paquets IP sortantde l'interface réseau. On va utiliser la commande "ping" pour vérifier que tout fonctionne comme prévu.
Test du réseau avant la commande tc:
$ ping 192.168.29.1
PING 192.168.29.1 (192.168.29.1) 56(84) bytes of data.
64 bytes from 192.168.29.1: icmp_seq=1 ttl=64 time=0.290 ms
64 bytes from 192.168.29.1: icmp_seq=2 ttl=64 time=0.204 ms
On simule un délai de 40 ms sur tout les paquets sortant (soit environ le délais sur une liaison ADSL):
sudo tc qdisc add dev eth0 root netem delay 40ms
Test du réseau après la commande tc:
$ ping 192.168.29.1
PING 192.168.29.1 (192.168.29.1) 56(84) bytes of data.
64 bytes from 192.168.29.1: icmp_seq=1 ttl=64 time=40 ms
64 bytes from 192.168.29.1: icmp_seq=2 ttl=64 time=40 ms
Pour revenir à la configuration initiale (sans simulateur), on utilise la commande suivante:
sudo tc qdisc del dev eth0 root
On vérifie que l'on retombe bien sur les caractéristiques normale du réseau:
$ ping 192.168.29.1
PING 192.168.29.1 (192.168.29.1) 56(84) bytes of data.
64 bytes from 192.168.29.1: icmp_seq=1 ttl=64 time=0.218 ms
64 bytes from 192.168.29.1: icmp_seq=2 ttl=64 time=0.209 ms
Simuler un délai de transit "normal"
Sur un réseau WAN, le délai de transit n'est jamais constant à travers le temps (surtout pour des liaisons de type Internet). Nous allons donc modifier la commande précédente pour intégrer une variation de délai (gigue de +/- 10ms) sur les paquets sortant:
sudo tc qdisc add dev eth0 root netem delay 40ms 10ms distribution normal
On obtient les caractéristiques suivantes:
$ ping 192.168.29.1PING 192.168.29.1 (192.168.29.1) 56(84) bytes of data.
64 bytes from 192.168.29.1: icmp_seq=1 ttl=64 time=36.9 ms
64 bytes from 192.168.29.1: icmp_seq=2 ttl=64 time=50.5 ms
64 bytes from 192.168.29.1: icmp_seq=3 ttl=64 time=33.1 ms
64 bytes from 192.168.29.1: icmp_seq=4 ttl=64 time=43.1 ms
64 bytes from 192.168.29.1: icmp_seq=5 ttl=64 time=32.5 ms
64 bytes from 192.168.29.1: icmp_seq=6 ttl=64 time=23.6 ms
...
Pour revenir à la configuration initiale (sans simulateur), on utilise la commande suivante:
sudo tc qdisc del dev eth0 root
Simuler une bande passante limite
Cette fonction ne fait pas partie de Netem mais utilise tout de même la commande tc pour se configurer.
Avant de commencer nous allons tester la capacité de notre réseau LAN avec la commande IPerf (à lancer en mode serveur UDP sur votre machine cible, 192.168.29.1 dans mon cas):
$ iperf -c 192.168.29.1 -u -b 10M
------------------------------------------------------------
Client connecting to 192.168.29.1, UDP port 5001
Sending 1470 byte datagrams
UDP buffer size: 110 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.29.222 port 47532 connected with 192.168.29.1 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 11.9 MBytes 10.0 Mbits/sec
[ 3] Sent 8505 datagrams
[ 3] Server Report:
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 3] 0.0-10.0 sec 11.9 MBytes 10.0 Mbits/sec 0.008 ms 0/ 8505 (0%)
On a donc bien un débit de 10 Mbps.
On commence par créer la racine de l'arbre des classes (avec une simulation de délai "normal" de 40ms):
sudo tc qdisc add dev eth0 root handle 1:0 netem delay 40ms 10ms distribution normal
Puis on y ajoute un "tuyau" limitant le trafic sortant à 512 Kbps:
sudo tc qdisc add dev eth0 parent 1:1 handle 10: tbf rate 512kbitbuffer 3200 limit 6000
On re-teste notre réseau:
$ iperf -c 192.168.29.1 -u -b 10M
------------------------------------------------------------
Client connecting to 192.168.29.1, UDP port 5001
Sending 1470 byte datagrams
UDP buffer size: 110 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.29.222 port 57589 connected with 192.168.29.1 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 11.9 MBytes 10.0 Mbits/sec
[ 3] Sent 8505 datagrams
[ 3] Server Report:
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 3] 0.0-10.3 sec 609 KBytes 486 Kbits/sec 14.351 ms 8081/ 8505 (95%)
On arrive bien à limiter le débit réseau sortant à 500 Kbps (un peu moins pour mon test).
Pour revenir à la configuration initiale (sans simulateur), on utilise la commande suivante:
sudo tc qdisc del dev eth0 root
Simuler une perte de paquets
La perte de paquets (ou "packet loss" dans la langue de Shakespeare) peut être simulé par Netem par la commande loss. Dans l'exemple suivant, nous allons simuler un lien WAN avec une perte de 0.1% des paquets sortant (soit 1 paquet perdu sur 1000 envoyé) avec un corrélation de 25% sur la probabilité que 2 paquets soit perdu de suite.
sudo tc qdisc add dev eth0 root netem loss 0.1% 25%
Pour revenir à la configuration initiale (sans simulateur), on utilise la commande suivante:
sudo tc qdisc del dev eth0 root
Simuler d'autres paramètres réseau
Il est également possible de simuler la duplication de paquets (commande duplicate), la corruption de paquets (commande corrupt) et le re-arrangement des paquets (commande gap).
Simuler également les paquets entrants
Imaginons que l'on veuille simuler une liaison de type ADSL, cette liaison est asymétrique en terme de débit. Il faut donc pouvoir simuler de manière différente le débit entrant (DOWNLOAD) du débit sortant (UPLOAD). Pour cela, il faut passer par la déclaration d'une interface réseau virtuelle (ifb) dans laquelle nous allons re-router les paquets entrants. Nous appliquerons nos paramètres réseau de simulation sur cette nouvelle interface.
Commençons par créer cette interface virtuelle:
# modprobe ifb
# ip link set dev ifb0 up
# tc qdisc add dev eth0 ingress
# tc filter add dev eth0 parent ffff: protocol ip u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb0
Puis appliquons un délai de 40ms comme vu dans le chapitre précédant:
# tc qdisc add dev ifb0 root netem delay 40ms 10ms distribution normal
Un exemple complet: simulation d'une liaison ADSL
Voici un script Shell (bash) permettant de mettre en place une simulation de type liaison ADSL sur votre réseau local:
#!/bin/bash
#
# limitbw.sh
# Nicolargo - 2009
## Nom de l'interface ou l'on doit faire la simulation
IF=eth0# Liaison sortante (UPLOAD)# Debit sortant
BWU=768kbit
# Délai de transit sortant
DELAYU=20ms
# % de paquets perdus sortant
LOSSU=0.01%# Liaison entrante (DOWNLOAD)# Debit entrant
BWD=2mbit
# Délai de transit entrant
DELAYD=20ms
# % de paquets perdus entrant
LOSSD=0.01%start() {# Liaison entrantemodprobe ifb
ip link set dev ifb0 up
tc qdisc add dev $IF ingress
tc filter add dev $IF parent ffff: \
protocol ip u32 match u32 0 0 flowid 1:1 \
action mirred egress redirect dev ifb0tc qdisc add dev ifb0 root handle 1:0 \
netem delay $DELAYD 10ms distribution normal \
loss $LOSSD 25%
tc qdisc add dev ifb0 parent 1:1 handle 10: \
tbf rate $BWD buffer 3200 limit 6000# Liaison sortantetc qdisc add dev $IF root handle 2:0 \
netem delay $DELAYU 10ms distribution normal \
loss $LOSSU 25%
tc qdisc add dev $IF parent 2:1 handle 10: \
tbf rate $BWU buffer 3200 limit 6000}stop() {tc qdisc del dev ifb0 roottc qdisc del dev $IF root# ip link set dev ifb0 down}restart() {stop
sleep 1
start}show() {echo "Liaison entrante"tc -s qdisc ls dev ifb0echo "Liaison sortante"tc -s qdisc ls dev $IF}case "$1" instart)echo -n "Starting WAN simul: "
start
echo "done"
;;stop)echo -n "Stopping WAN simul: "
stop
echo "done"
;;restart)echo -n "Restarting WAN simul: "
restart
echo "done"
;;show)echo "WAN simul status for $IF:"
show
echo ""
;;*)echo "Usage: $0 {start|stop|restart|show}"
;;esacexit 0
Les types de comptes d’utilisateurs windows
Les types de comptes d’utilisateurs Windows

Il existe plusieurs types de comptes d’utilisateurs dans
Windows :
- Comptes
Administrateur : Ils permettent aux utilisateurs d’ouvrir une session en
tant qu’administrateurs. Ce compte peut exécuter n'importe quelle instruction sur le système .
- Comptes Système : Ils permettent au système d’exploitation d’accéder aux ressources.
- Comptes Invité : Ils permettent aux utilisateurs d’ouvrir une session temporairement sur
l’ordinateur avec des droits très limités. Pour plus de sécurité, pensez à
désactiver le compte Invité.
- Comptes locaux: Chaque ordinateur Windows gère son propre jeu de comptes, ou comptes locaux, qui permettent aux utilisateurs d’ouvrir une session sur l’ordinateur et non sur le domaine. Les comptes locaux par défaut incluent un compte Administrateur local, un compte Invité local et le compte Système.
- Comptes de domaine : Ils permettent aux utilisateurs d’ouvrir une session sur le domaine où les comptes peuvent être gérés de façon centralisée. Dans un domaine Active Directory, les comptes d’utilisateurs se trouvent dans un emplacement central et sont enregistrés dans le service d’annuaire Active Directory. Ils sont donc considérés comme des comptes de domaine. Il ne faut pas confondre les comptes de domaine avec le compte local d’un ordinateur individuel.
NAGIOS La supervision Informatique
NAGIOS
I. Cahier des charges
1. Réseau à superviser
Le réseau que nous devons
superviser est celui-ci :

Il sera composé :
- D'un serveur "Windows Server 2003" qui permettra la gestion des utilisateurs du réseau :
- Stockage des données et identifications des utilisateurs
- D'un serveur "Nagios" qui s'occupera de la supervision du réseau, de la centralisation et de l'analyse des informations du réseau
- D'un poste client "Windows XP"
- D'un poste client "Linux"
- D'un routeur "Cisco" qui permettra de relier les différents équipements du réseau et d'être relié au réseau extérieur (à Internet).
2. Règles sur le réseau
Sur le routeur, un firewall sera configuré grâce à des ACL (Access Control List) permettant
l'autorisation ou le refus
de certaines connections.
Le firewall
devra:
- Autoriser le protocole SMTP (pour l'envoi de mail) sortant mais pas entrant
- Autoriser le protocole IMAP (pour la réception de mail) entrant et sortant
- Autoriser le protocole HTTP entrant et sortant (pour le web)
- Autoriser le protocole ICMP entrant et sortant (pour l'envoi et la réception de PING)
- Refuser tous les autres protocoles dans les deux sens
Pour résumer :

II.
Fonctionnement et installation de Nagios
1. Présentation de Nagios
Nagios est un logiciel de supervision de réseau libre sous licence GPL qui fonctionne
sous Linux.Il a pour fonction de surveiller les hôtes et services spécifiés, alertant l'administrateur des
états des machines et équipements
présents sur le
réseau.Bien qu'il fonctionne dans un environnement Linux, ce
logiciel est
capable
de superviser toutes sortes de systèmes d'exploitation (Windows XP, Windows 2000, Windows 2003 Server, Linux, Mac OS entre autres) et également des équipements réseaux grâce au protocole SNMP.
Cette polyvalence permet d'utiliser Nagios dans toutes sortes d'entreprises, quelque soit la topologie du réseau et les systèmes d'exploitation utilisés au sein de l'entreprise.
Ce logiciel est composé de trois parties:
Cette polyvalence permet d'utiliser Nagios dans toutes sortes d'entreprises, quelque soit la topologie du réseau et les systèmes d'exploitation utilisés au sein de l'entreprise.
Ce logiciel est composé de trois parties:
- Le moteur de l'application, qui gère et ordonnance les supervisions des différents équipements
- Les Plugins qui servent d'intermédiaire entre les ressources que l'on souhaite superviser et le moteur de Nagios. Il faut bien noter que pour accéder à une certaine ressource sur un hôte, il faut un plugin coté Nagios et un autre coté hôte administré.
- L'interface web qui permet d'avoir une vue d'ensemble des états de chaque machine du parc informatique supervisé et ainsi pouvoir intervenir le plus rapidement possible en ciblant la bonne panne.
2. Fonctionnement de Nagios
Le principe de supervision de Nagios repose sur l'utilisation de plugins, l'un installé sur
la machine qui supporte Nagios, et l'autre sur la machine que l'on souhaite superviser. Un plugin est un programme modifiable, qui peut être écrit dans plusieurs langages possibles, selon les besoins,
et qui servent à récupérer les
informations souhaitées.
Nagios, par
l'intermédiaire de son plugin, contact
l'hôte
souhaité et
l'informe des
informations qu'il
souhaite recevoir.
Le plugin correspondant installé sur la machine
concernée reçoit la requête envoyée par Nagios et
ensuite va chercher dans
le système de sa machine les informations
demandées.
Il renvoi
sa réponse
au plugin Nagios, qui ensuite le transmet au moteur
de Nagios afin
d'analyser
le résultat obtenu et
ainsi mettre à jour l'interface
web.
Il existe
deux types de récupération d'informations: La récupération active et la
récupération passive.
La différence entre les deux types est l'initiative de la récupération. Dans le premier
type, à savoir le type actif, c'est Nagios qui a toujours cette initiative. C'est lui qui décide
quand il envoie une requête lorsqu'il
veut récupérer une information.
Alors que lors d'une récupération passive, l'envoi d'information est planifié en local,
soi à partir d'une date, soit en réaction à un événement qui se déroule
sur la machine administrée.
Pour notre projet, nous avons décidé d'utiliser le type de récupération active, c'est-à- dire que Nagios prend l'initiative d'envoyer une requête pour obtenir des informations. Ceci évite donc de configurer les postes à superviser.
La demande d'informations se fait grâce à l'exécution
d'une commande de la part de
Nagios. Une commande
doit
obligatoirement
comporter
des arguments afin
de
pouvoir
chercher les
bonnes
informations
sur les bonnes machines.
Ces arguments
sont l'adresse IP de l'hôte sur lequel aller chercher l'information, la limite
de la valeur de l'information recherchée pour laquelle l'état 'attention'
sera décidé, idem
pour la valeur 'critique', et enfin
d'autres
options qui varient selon le
plugin utilisé.
Pour ne pas devoir à créer une commande
par machine supervisée et par information recherchée, nous pouvons remplacer les arguments par des variables, et ainsi réutiliser la
commande plusieurs fois, en remplaçant la bonne variable. Nous avons alors la possibilité
de travailler avec
des
services. Lors de la création d'un service, il faut l'associer à un ou plusieurs
hôtes puis à une commande.
Ensuite Nagios
remplace
automatiquement la
variable
de
l'adresse
IP dans
la
commande, grâce à la
liste d'hôtes associée au
service.
Puis on doit
définir manuellement dans
le service les
autres variables nécessaires
à la commande .

Un fois que Nagios à reçu les informations dont il avait besoin sur l'état
des hôtes, celui-ci peut construire des notifications sur l'état du réseau,
afin d'en informer l'administrateur.
Lorsque Nagios effectue une notification, il attribut des états aux hôtes,
ainsi qu'aux services.
Un hôte peut avoir les états suivants:
- Up : en fonctionnement
- Down : éteint
- Inaccessible
- n attente Les différents états d'un service sont: OK
- Attention
- Critique
- En attente
- Inconnu

III.
Les plugins
1. Plugins principaux
Nagios possède une importante
communauté sur Internet. Grâce
à celle-ci, de
nombreux utilisateurs ont créés des plugins permettant à Nagios d'aller récupérer des informations sur
des équipements du
réseau (PC, routeurs,
serveurs, …)
Les plugins n'utilisent pas tous le même protocole
pour échanger les informations. Le protocole utilisé est dans la plupart des cas un facteur décisif sur le
choix des plugins à utiliser.
Un seul plugin Nagios ne peut pas aller chercher
toutes les informations sur les équipements du réseau: En effet, chaque plugin
n'a accès qu'à certaines informations (exemple: un plugin peut aller chercher
l'occupation du disque dur, et un autre l'occupation du processeur d'un PC).
Pour superviser un parc informatique, il est donc nécessaire de mettre en place
plusieurs plugins.
De plus, certains
plugins peuvent aller
chercher des
informations sur des clients
uniquement sur certains systèmes d'exploitation (c'est le cas
du plugin check_nt qui
peut chercher des informations
uniquement sur des équipements Windows).
Les principaux plugins
utilisés
par nagios sont :
- check_disk : Vérifie l'espace occupé d'un disque dur
- check_http : Vérifie le service "http" d'un hôte
- check_ftp : Vérifie le service "ftp" d'un hôte
- check_mysql : Vérifie l'état d'une base de données MYSQL
- check_nt : Vérifie différentes informations (disque dur, processeur …) sur un système d'exploitation Windows
- check_nrpe: Permet de récupérer différentes informations sur les hôtes
- check_ping: Vérifie la présence d'un équipement, ainsi que sa durée de réponse
- check_pop: Vérifie l'état d'un service POP (serveur mail)
- check_snmp : Récupère divers informations sur un équipement grâce au protocoleSNMP (Simple Network Management Protocol)
Il est possible
de créer
son propre plugin. Dans ce cas,
il faudra les
créer de la sorte
que celui renvoie à nagios :
- L'état du résultat (OK, CRITICAL, DOWN, UP, …)
- Une chaine de caractères (pour donner le détail du résultat)
2. Plugins retenus
Après avoir consulté les différents plugins
existants, nous avons choisi ceux qui correspondaient
à notre cahier des charges.
Nous avons retenus les plugins suivants :
- check_nt
- check_nrpe
- check_snmp
- check_ping
A. Check_nt
Le plugin
Check_nt est un plugin récent qui
permet de superviser
très facilement
des P
dont le système d'exploitation est Windows.
Check_nt permet de récupérer sur un système Windows les informations suivantes :
dont le système d'exploitation est Windows.
Check_nt permet de récupérer sur un système Windows les informations suivantes :
L'espace occupé sur le disque dur, le
temps depuis le démrrage de l'ordinateur,
la version du plugin NsClient ++ (voir
ci-dessous),
occupation du processeur,
occupation
de la mémoire, état
d'un service.
B. Check_nrpe
Le plugin Check_nrpe
est un plugin qui
permet de superviser des PC
dont le système
d'exploitation est Windows ou Linux.
Check_nrpe utilise une connexion SSL (Secure Socket Layout) pour
aller chercher
les informations sur les postes.
Ceci
permet de crypter
les trames d'échanges.
C. Check_snmp
Le plugin Check_snmp
est un plugin qui
permet de superviser
tous les équipements. En revanche,
il est très instable pour
superviser les
PC.
Dans notre projet,
nous utiliserons check_snmp pour superviser le routeur.
D. Check_ping
Le plugin Check_ping est un plugin
qui permet de vérifier qu'un hôte
est bien joignable.
Usage : Pour vérifier qu'un hôte est joignable, Nagios exécute une
commande ayant
la syntaxe
suivante :
check_ping -H <adresse de l'hote> -w <temps maxi de reponse>,<Pourcentage de réussite des pings> -c
<temps maxi de reponse>,<Pourcentage de réussite des pings>
Avec:
-w : Seuil pour lequel
le résultat
est considéré comme
une alerte
-c : Seuil pour lequel le résultat
est considéré comme
critique
Pour notre projet, on testera la
présence du
routeur
RT (192.168.104.5). En effet, ci celuici ne
répond
plus, on peut considérer
que l'on est plus connecté à Internet.
IV.
INSTALLATION
DE NAGIOS SUR FEDORA
On commence par l'installation de Nagios et des différents
plugins.
# yum -y install nagios
# yum -y install nagios-plugins
# yum -y install nagios-plugins-ping nagios-plugins-tcp nagios-plugins-udp nagios-plugins-http
nagios-plugins-dns
nagios-plugins-dns
nagios-plugins-smtp nagios-plugins-ldap nagios-pluginspgsql nagios-plugins-mysql
Vient ensuite la configuration du serveur web (Apache dans notre exemple, mais on peut
en utiliser
un
autre).
On
doit
pour
cela modifier le fichier nagios.conf dans
/etc/httpd/conf.d/
pour autoriser l'accès depuis toutes les sources.
# vi /etc/httpd/conf.d/nagios.conf

doit également
générer un couple login/password pour accéder à l'interface Web
d'administration. Pour cela,
il faut:

Dans ma configuration il a aussi fallu que je passe ma Fedora en mode SELINUX permissive,
sinon les scripts CGI de Nagios ne s'exécutaient pas.

On active le service par la commande :
# service nagios start
Après en redémarre le système par la commande :
# reboot
# service nagios start
Après en redémarre le système par la commande :
# reboot
Enfin on teste le nagios


Groupes d'hôtes Descriptif de Nagios

Les services Descriptif de Nagios

Hôte problème
Descriptif de Nagios

L'information
sur le rendement de
Nagios

L'information de processus de Nagios

Les Checkcommands
Nagios

2-D Carte de Nagios

Le menu Host Detail :Cette page résume l'état global des machines de votre réseau, avec leurs états (ACTIF, EN PANNE ...)

Le menu
Status Overview :Cette page affiche tous
les hôtes par groupes,
cela permet une vue
rapide
sur un sous-ensemble
de votre parc

Le menu
Status Map :
Cette page représente
l'implantation
de vos hôtes sous plusieurs

formes graphiques.
Vous avez un aprecu de
la topologie de vos hôtes en 2D ou
en 3D pour le fun
(installez un plugin VRML)

Le menu Scheduling Queue :Cette page liste les services qui vont être testés prochainement. C'est ici que vous pouvez demander le test d'un service manuellement (l'icône montre au poignet), suite à une modification de votre configuration par exemple

V. Installation et configuration NSClient++
La supervision
des machines Windows se fait grâce à l'agent NSClient++ qui doit être installé sur la
machine distante
à superviser.
“NSClient++” se base sur
une architecture client/serveur. La partie cliente (nommée
check_nt),
doit être disponible sur
le serveur Nagios. La partie
serveur (NSClient++) doit être installée sur chacune des machines
Windows à surveiller.
1. Installation
1. Installation


On saisit l’adresse ip de serveur nagios dans la case Aloowedhost . On termine l’installation par start service et finish
2. Configurer NSClient + +
Pour autoriser
le service intégrer
au bureau
on passe a outils d’administration via panneau de
configuration on sur services
puis nsclient++
Double click et
on activer

Éditez le fichier NSC.INIfile
(situé dans le répertoire C:\NSClient++) et effectuez les changements
suivants :
Décommentez tous les
modules
listés dans la section [modules],
exceptés
CheckWMI.dll et RemoteConfiguration.dll
CheckWMI.dll et RemoteConfiguration.dll
Exigez optionnellement un mot de passe
des clients en remplaçant
l'option password dans
la Section
Décommettez l'option
allowed_hosts dans la section [Settings].
Ajoutez l'adresse IP du serveur Nagios
à cette ligne, ou laisser vider pour autoriser n'importe
quel hôte à se
connecter.
Assurez-vous que l'option port
dans la section [NSClient] soit décommentée
Configurer le Pare-feu
Windows pour permettre NSClient + +
d'accès:
Exception à ajouter sur le pare-feu Windows pour autoriser l'accès à NSClient ++ Démarrer -> Panneau de configuration -> Windows Firewall -> Exceptions -> Ajoute
un programme -> Parcourir C: \ Program Files \ NSClient + + \ NSClient + +. Exe
Exception à ajouter sur le pare-feu Windows pour autoriser l'accès à NSClient ++ Démarrer -> Panneau de configuration -> Windows Firewall -> Exceptions -> Ajoute
un programme -> Parcourir C: \ Program Files \ NSClient + + \ NSClient + +. Exe

On passe au serveur
nagios de terminer
la configuration
Ouvrez le fichier windows.cfg pour édition
Fedora: # vi /usr/local/nagios/etc/objects/windows.cfg
Ajouter une nouvelle définition d'hôte
pour la machine Windows que vous souhaitez superviser.
Si c'est la « première » que vous
supervisez, vous pouvez simplement modifier l'exemple de définition d'hôte dans windows.cfg. Remplacez les champs host_name,
alias,
et adressé par les
valeurs appropriées pour
votre machine
Windows.

Maintenant vous pouvez ajouter
quelques
définitions
de services (dans le
même fichier de
configuration) pour indiquer à Nagios de superviser différents
aspects de la machine Windows.Ajoutez la définition de
service suivante pour contrôler
la version de l’addonNSClient++ tournant
sur le serveur Windows. Cela devient
utile quand il s'agit de mettre à jour des serveurs Windows
vers une nouvelle version
de l’addon, en
vous permettant de déterminer quelles
sont les machines Windows nécessitant
une mise à jour vers la dernière version de NSClient++.
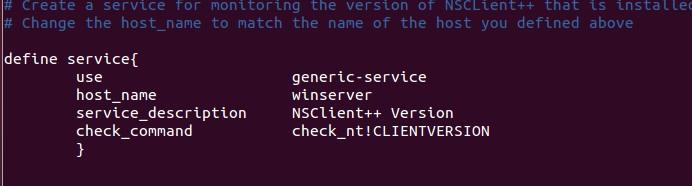
Ajoutez la définition
de service suivante pour
superviser le temps écoulé depuis le
dernier re/démarrage du serveur Windows.

Ajoutez la définition
de service suivante pour
superviser la charge CPU
du serveur Windows
et générer une alerte CRITICAL si la charge CPU des
5 dernières minutes est
égale à 90% ou plus ou une alerte WARNING si la
charge CPU
des 5 dernières minutes
est égale à 80% ou
plus.

Voilà pour le moment. On a ajouté des
services simples qui devraient
être supervisés
sur les machines Windows. Enregistrez le
fichier de configuration.
Maintenant, il faut enregistrer le fichier
et vérifier s’il
n’a
pas des erreurs avec la
commande :
linux:~ # /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Pius redémarrer Nagios

Vidéos similaires
GRANDES CATEGORIES















Messages populaires
-
Installation pas à pas de Nagios Trêve de blabla, entrons directement dans le vif du sujet avec l'installation d...
-
 Si vous souhaitez scanner une plage d’adresse IP sur votre réseau afin de vérifier la disponibilité d’une ou plusieurs...
Si vous souhaitez scanner une plage d’adresse IP sur votre réseau afin de vérifier la disponibilité d’une ou plusieurs... -
Installation de Cacti sous Debian Les systèmes informatiques d'entreprise associent une diversité de services proposés (rout...
-
 C’est quoi le DFS ? I. Présentation Ce premier article a pour but d’expliquer ce qu’est le DFS, accessible dans u...
C’est quoi le DFS ? I. Présentation Ce premier article a pour but d’expliquer ce qu’est le DFS, accessible dans u... -
Qu’est-ce que le NAT ? Commençons par la signification du NAT, Network Address Translation (en Français Translation d’Adresse Réseau)...
-
 Création d’une règle de pare-feu avec un Fortigate I. Présentation Après avoir découvert ce qu’est un Fortinet dans un premier ...
Création d’une règle de pare-feu avec un Fortigate I. Présentation Après avoir découvert ce qu’est un Fortinet dans un premier ... -
 Active Directory I. L’Active Directory L’Active Directory est un annuaire LDAP pour les systèmes d’exploitation Windows, l...
Active Directory I. L’Active Directory L’Active Directory est un annuaire LDAP pour les systèmes d’exploitation Windows, l... -
 IPerf: des exemples… Nous commençons l'année 2008 avec un billet regroupant des exemples d'utilisation d'IPerf, l'...
IPerf: des exemples… Nous commençons l'année 2008 avec un billet regroupant des exemples d'utilisation d'IPerf, l'... -
 Comment exécuter un script PowerShell Dans l’article comment installer et vérifier le bon fonctionnement de PowerShell , nous av...
Comment exécuter un script PowerShell Dans l’article comment installer et vérifier le bon fonctionnement de PowerShell , nous av... -
 Routage RIP Définitions Avant de parler de routage RIP, il faut que j’explique qu’est-ce qu’un routeur et quel est son but. Le ...
Routage RIP Définitions Avant de parler de routage RIP, il faut que j’explique qu’est-ce qu’un routeur et quel est son but. Le ...

{kind=link}
{kind=link}
pobular post

Fourni par Blogger.
Recent Stories
CONNECTER AVEC FACEBOOK
Sponsors
Chercher
Archives
Contactez Moi